Private and Fair Data Generation

Differential privacy
We often hear about the importance of privacy and how crucial it is to preserve the privacy of sensitive data. In particular, some governmental organizations such as the EU and US government are beginning to require companies that handle personal and sensitive data to employ privacy mechanisms in order to protect their sensitive data (see the GPR of the EU and the CCPA of California that require that the privacy of the individuals whose data is being used be maintained). There are many standards of privacy that have been explored in the literature. For example, we could drop identifying columns from the database tables or use a standard called k-anonymity to protect our data. However, these have been shown to be vulnerable to attacks, e.g., if an attacker knows the encryption algorithm or can somehow post-process the data, they can glean sensitive information about sepecific individuals from it. To ensure that our data is protected from such attacks, we can use an approach called Differential Privacy (DP) [2]. Differential privacy is the gold standard in offering mathematically rigorous bounds on privacy leakage while offering utility through multiple data releases, even in the presence of background information.
A randomized mechanism $\mathcal{M}$ satisfies $\epsilon$-DP if for all $S\subseteq Range(\mathcal{M})$ and for all pairs of databases that differ by a single record, $D, D’$, $$Pr[\mathcal{M}(D)\in S] \leq e^\epsilon Pr[\mathcal{M}(D’)\in S]$$
Private data can be queried directly using designated DP mechanisms. However, the accuracy of the results depends heavily on the privacy budget, especially when multiple queries need to be answered. Furthermore, the results may be inconsistent with each other. Moreover, there are certain functions that are more difficult to support, e.g., provenance tracking and providing explanations to query results. A prominent alternative is using differentially-private synthetic data generators (SDGs) to produce a synthetic copy of the private data, which can be used repeatedly to answer multiple queries without spending additional privacy budget. This is due to the post-processing property of DP: “A data analyst, without additional knowledge about the private database, cannot compute a function of the output of a private algorithm M and make it less differentially private”.
This means that If the synthetic data was generated in a differentially private way, we can use it any way as much as we want without compromising the privacy of the sensitive data!
Two mechanisms that will come in handy in the article are the Gaussiam and the Exponential mechanisms.
The Gaussian mechanism
This is a DP primitive for answering numerical queries and is often used to construct more complex DP mechanisms.
Given a query $q$ and a database, $D$, the randomized algorithm which outputs the following query answer is differentially private. $$q(D) + \mathcal{N}(0,\sigma^2)$$ where $\mathcal{N}(0,\sigma)$ denotes a sample from the Normal distribution with mean $0$ and scale $\sigma = \frac{c \Delta_2 q}{\epsilon}$, $c$ is a constant that adheres to specific conditions, $\epsilon$ is the privacy budget, and $\Delta_2 q$ is the global $l_2$-sensitivity of $q$ (i.e., the maximum $l_2$ change in the output of $q$ for two databases that differ by a single record).
The Exponential Mechanism (EM)
EM is a DP primitive for queries that outputs categorical data instead of numerical data. The exponential mechanism releases a DP version of a categorical query $q$ by randomly sampling from its output domain $\mathcal{R}$. The probability for each individual item to be sampled is given by a pre-specified score function $u$. The score function takes as input a dataset $D$ and an element in the domain $e \in \mathcal{R}$ and outputs a numeric value that measures the quality of $e$. Larger values indicate that $e$ is a better output with respect to the database and as such increases the probability of $e$ being selected.
Given a database $D$, a range of outputs $\mathcal{R}$, real-valued score function $u(D, e)$ that gives the utility of $e\in \mathcal{R}$ with respect to $D$, and a privacy budget $\epsilon$, the Exponential mechanism $\mathcal{M}_E$ returns $e\in \mathcal{R}$ with probability $c\cdot exp({\frac{\epsilon u(D, e)}{2\Delta u}})$, where $c$ is a positive constant and $\Delta u$ is the global sensitivity of $u$.
Private Data Generation Approaches
We can now discuss different approaches for private synthetic data generation. These approaches can be broadly categorized into three classes:
- Workload-based approaches: these approaches usually take a query workload and aim to privately release synthetic data that minimizes the error for these queries.
- Explicit statistical model-based approaches: These approaches usually learn an explicit and non-private low-dimensional noisy statistics of the data and sample from it to generate synthetic data.
- GAN-based approaches: These approaches train a generator and a discriminator to generate data such that the generator is able to generate data that the discriminator cannot identify as “fake”, while adding noise to the gradients.
A good code repository that implements multiple of these approaches can be found here.
One example of a workload-based approach is MWEM [12] that repeatedly uses the Exponential Mechanism to find queries that are poorly served by the current approximated data distribution of the underlying private data and then improve it.
An example of the explicit statistical model-based approach is PrivBayes [13] which learns a Bayesian network that attempts to summarize the statistics of the private database. Each edge represents a mutual information between two attributes, and edges for the network are selected using the EM with a utility function that approximates this mutual information. Then, the network is sampled to generate the synthetic data.
Finally, an example of a GAN-based approach is DP-GAN [14] where a form of GAN, called WGAN, is used to teach the generator how to mimic the data distribution. To ensure that the training process of the WGAN satisfies DP, the gradient is first clipped or truncated so that its value will always be in the interval [-a,a], ensuring that its sensitivity is bounded. Then, Gaussian noise is added to it, at the necessary scale to satisfy DP [3].
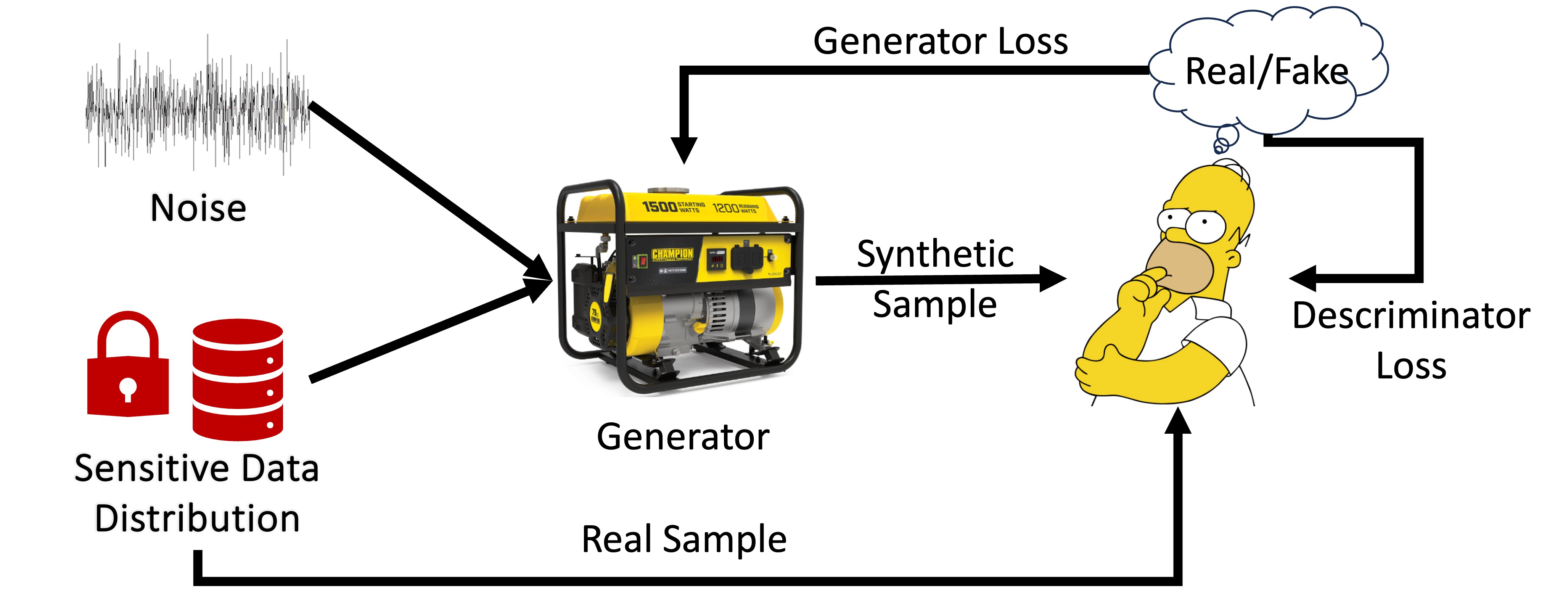
Incorporating Constraints into Private Data Generation With Explicit statistical models
Why should we add constraints to the data generation process? As indicated by [5], the synthetic data generation process may preserve or even exacerbate properties in the data that make it, for example, unfair!
In this aspect, there has been a signiffcant effort in recent years to both define fairness [5, 6, 7, 8, 9, 10], and develop frameworks to understand and mitigate bias [11, 16]. Among these, causal approaches for fairness propose a principled approach of measuring the effect of protected attributes on the outcome attributes. These works consider the causal relationship between protected attributes, i.e., those that cannot be explicitly used in decision making, admissible attributes, i.e., those that can be explicitly used in decision making, and outcome attributes that are the prediction targets. Prior works have proposed frameworks for pre-processing steps to repair the data and ensure causal fairness. Notably, none of these have done so while under the constraint of DP as they assume the data is accessible.
Our solution [1] combines the state-of-the-art DP synthetic data generation system, MST [15] (shown to be the best performing mechanism in terms of minimizing the discrepancy between the private database and the generated one [4]) with the robust causal fairness definition of Justifiable Fairness [11] to generate data that ensures fairness while satisfying DP. In justifiable fairness, the data is defined to be fair if there is no directed path in the causal graph between the protected attribute and the outcome attribute that does not pass through an admissible attribute in a graphical model which describes the data. Specifically, we augment the first step shown in Figure 1 to satisfy the graph properties needed for Justifiable Fairness and provides a guarantee that the data generated in the second step will be fair, under a common assumption.
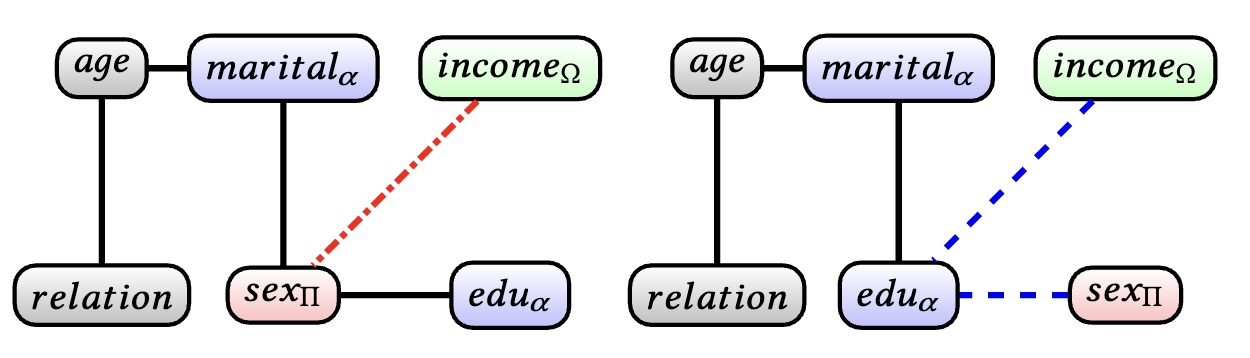
Example 1. Consider the Adult dataset with the attributes age, marital-status (marital), education (edu), sex, income, and relationship. The MST system first learns the 2-way attribute marginals and then samples from them to generate a synthetic database instance. Figure 2a shows the graphical representation of the database attributes, generated by MST. Here, protected attributes are denoted with a subscript $\Pi$ (and are colored red), admissible attributes are denoted with a subscript (and are colored blue) and the outcome attribute with a subscript $\Omega$ (and is colored green). The edges denote attributes that have a strong correlation between them in the private database. Note that the protected attribute sex (denoted by a subscript $\Pi$ and colored red) has an edge to the income attribute which is the outcome. Intuitively, any synthetic database that will follow the distribution dened by this graph will have a direct dependence between the attribute sex and the attribute income, resulting in unfair data (while the graphical model is not a causal graph, we rely on the graphical properties of justifiable fairness). On the other hand, Figure 2b shows an alternative graphical representation of the dependencies, generated by PreFair. In this graph, the path from sex to income passes through the admissible attribute education (the dashed edges colored blue). Intuitively, in any synthetic data that will adhere to this distribution, the in uence of the sex attribute on income will be mitigated by the education attribute, which is considered admissible, so, it is allowed to directly influence the outcome.
Ensuring that PreFair is useful gives rise to several challenges. In particular, we tackle the following challenges: (1) adapting the denition of fairness to undirected graphical models, (2) making a connection between the graphical model and the data to guarantee that a fair model would lead to the generation of fair data, and (3) providing efficient algorithms that will generate fair data while remaining faithful to the private data and satisfying DP.
These are our contributions in this work:
- We propose PreFair, the first framework, to our knowledge, that generates synthetic data that is guaranteed to be fair and differentially private. PreFair combines the state-of-the-art synthetic data generation approach that satisfies DP [15] with the definition of justifiable fairness [11].
- We provide a novel model for fair data generation that relies on probabilistic graphical models and characterize the desiderata for the sampling approach to generate justifiably fair data.
- We prove that finding the optimal fair graph in our model is NP-hard even in the absence of privacy.
- Due to the intractability of the problem, we devise two solutions: (1) an algorithm that provides an optimal solution for an asymptotically large privacy budget and (2) a greedy algorithm that uses heuristics to construct the graph, while still guaranteeing fairness but possibly reducing the faithfulness to the private data.
- We perform an extensive experimental evaluation to test PreFair and show that our greedy approach can generate fair data while preserving DP and remaining faithful to the private data. We further show that our greedy approach does not incur major overhead in terms of performance.
Incorporating Constraints into Other Private Data Generation Approaches
Other approaches will require different interventions than our solution for explicit statistical models. For example, our approach for augmenting GAN-based approaches may be inspired by previous work that provides solutions for fair data generation without privacy by incorporating gradient clipping and noise addition. We are actively working in this direction.
References
[1] Pujol, D., Gilad, A., Machanavajjhala, A. (2023). PreFair: Privately Generating Justifiably Fair Synthetic Data. VLDB 2023.
[2] Dwork, C., & Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 9(3-4), 211-407.
[3] Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., & Zhang, L. (2016). Deep learning with differential privacy. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 308-318.
[4] Tao, Y., McKenna, R., Hay, M., Machanavajjhala, A., & Miklau, G. (2021). Benchmarking Differentially Private Synthetic Data Generation Algorithms. arXiv preprint arXiv:2112.09238.
[5] Ganev, G., Oprisanu, B., & De Cristofaro, E. (2022). Robin Hood and Matthew Effects: Differential Privacy Has Disparate Impact on Synthetic Data. In Proceedings of the International Conference on Machine Learning (ICML) (Vol. 162, pp. 6944-6959)
[6] Calmon, F. P., Wei, D., Vinzamuri, B., Ramamurthy, K. N., & Varshney, K. R. (2017). Optimized Pre-Processing for Discrimination Prevention. In Advances in Neural Information Processing Systems (NIPS) (pp. 3992-4001)
[7] Chouldechova, A. (2017). Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Big Data, 5(2), 153-163
[8] Corbett-Davies, S., Pierson, E., Feller, A., Goel, S., & Huq, A. (2017). Algorithmic Decision Making and the Cost of Fairness. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD) (pp. 797-806). ACM.
[9] Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012). Fairness through awareness. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference (pp. 214-226).
[10] Kilbertus, N., Rojas-Carulla, M., Parascandolo, G., Hardt, M., Janzing, D., & Schölkopf, B. (2017). Avoiding Discrimination through Causal Reasoning. In Advances in Neural Information Processing Systems (NIPS) (pp. 656-666).
[11] Salimi, B., Rodriguez, L., Howe, B., & Suciu, D. (2019). Interventional Fairness: Causal Database Repair for Algorithmic Fairness. In Proceedings of the 2019 ACM SIGMOD International Conference on Management of Data (SIGMOD) (pp. 793-810).
[12] Hardt, M., Ligett, K., & McSherry, F. (2013). A Simple and Practical Algorithm for Differentially Private Data Release. In Advances in Neural Information Processing Systems (NIPS) (pp. 2339-2347). Curran Associates, Inc.
[13] Zhang, J., Cormode, G., Procopiuc, C. M., Srivastava, D., & Xiao, X. (2014). PrivBayes: private data release via Bayesian networks. In Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD) (pp. 1423-1434).
[14] Xie, L., Lin, K., Wang, S., Wang, F., & Zhou, J. (2018). Differentially Private Generative Adversarial Network. CoRR, abs/1802.06739.
[15] McKenna, R., Miklau, G., & Sheldon, D. (2021). Winning the NIST Contest: A scalable and general approach to differentially private synthetic data. CoRR, abs/2108.04978.
[16] Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., & Venkatasubramanian, S. (2015). Certifying and Removing Disparate Impact. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD) (pp. 259-268).